


This blog focuses on the dire circumstances of a catastrophic recovery involving the entire system. There is a companion blog, Recover Quickly With Surgical Precision, that focuses on isolated recovery from the IBM Z Cyber Vault.
The IBM Z Cyber Vault solution for resiliency is the newest concept for addressing data corruption, whether through malicious intent, human error or failure of hardware or software. It provides an air gapped backup of the operating system and all data. The Safeguarded copy process is designed to take copies at a user specified interval. This blog won’t describe or explain the details of the entire process but rather to discuss one part of the software stack that brings added value to this resiliency solution. It provides some very specific functions and capabilities to make the recovery process simpler, faster, and less manual.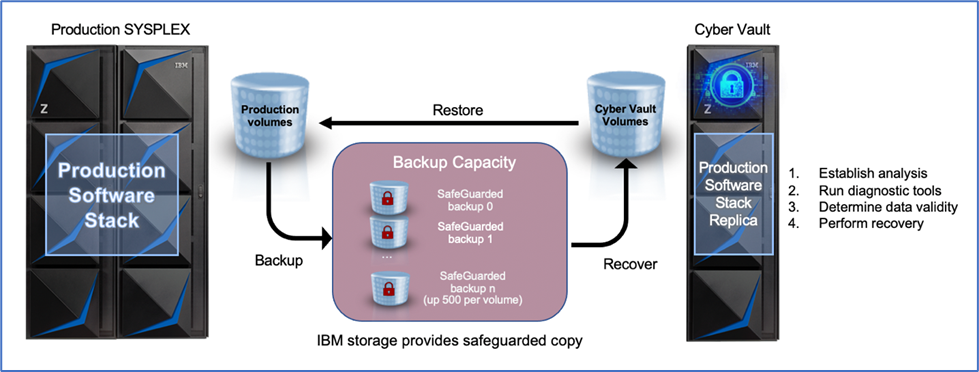
The IBM Z Batch Resiliency (IZBR) software is designed to ensure that all the non-database managed data, such as sequential and VSAM files, has the same resiliency as the database managed data. Db2 and IMS have recovery logs and specific tools that do not exist for the non-database managed data, and it is up to each application to be sure files are backed up and that they can be recovered.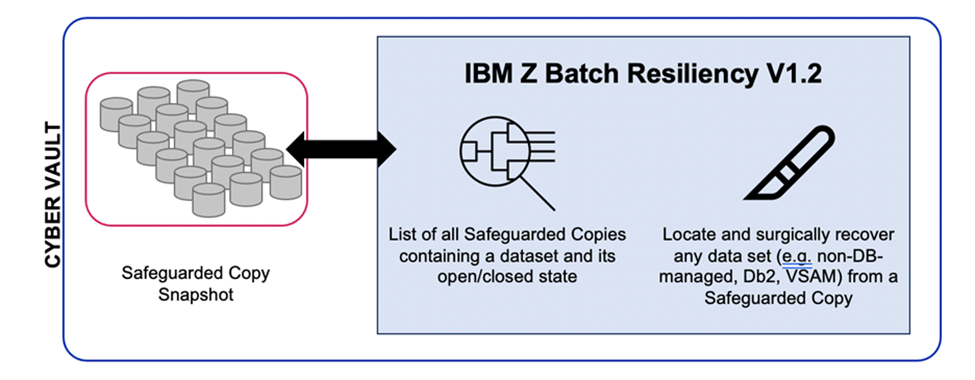
This can become a very complex and convoluted process. The “when in doubt, back it up” approach often leads to too many backups and wasted resources. In addition, when a failure occurs, it is often difficult to know the best backup version to use for recovery. IZBR is designed to solve this problem by understanding the use of the data, monitoring all the backups, and ensuring that the right backups are taken. When an error occurs, the most appropriate backup can be used to restore the data in minutes. IZBR uses extensive analytics of various data sources such as SMF data, input from the scheduler, and other sources to store an inventory of all critical data sets and their backups.
The IZBR solution has been enhanced to provide some of these capabilities for the Safeguarded copies that include non-database managed data. One of the key values is that IZBR provides information on the status of the non-database managed data at the time of the Safeguarded copy. While the database management tools can process “fuzzy” backups, which are backups of open files, non-database managed data sets are considered unreliable if they are open for output. Because the Safeguarded copy is done with no consideration of the state of the data sets, it is very likely that some non-database managed data sets will be open for output at the time of a backup. IZBR’s Cyber Vault Health Check report provides a list of all data sets that are open for output at the time of the Safeguarded copy. This report could be used to identify the best Safeguarded copy to use (the one with the fewest data sets open for write) or it might be used to find alternative Safeguarded copies for selected data sets that are unusable from the primary Safeguarded copy that is being used.
In addition to being able to recover non-database managed data, the surgical recovery capabilities can be used to recover any data set from the Safeguarded copies. This is a key capability that can greatly simplify and speed recovery. Surgical recovery will be described in greater detail below.
Of particular interest to the IBM Z Cyber Vault solution are IZBR’s Timeliner reports. The Timeliner report, specifically the Reverse Cascade Report, can be used to, from a particular point in time, look backwards for a data set and see all the jobs that have used or influenced this data set. It will display these jobs and show, for each job, the data sets that were used both as input or output. This information provides analytics to forensically help identify the points where a data set could have become corrupted.
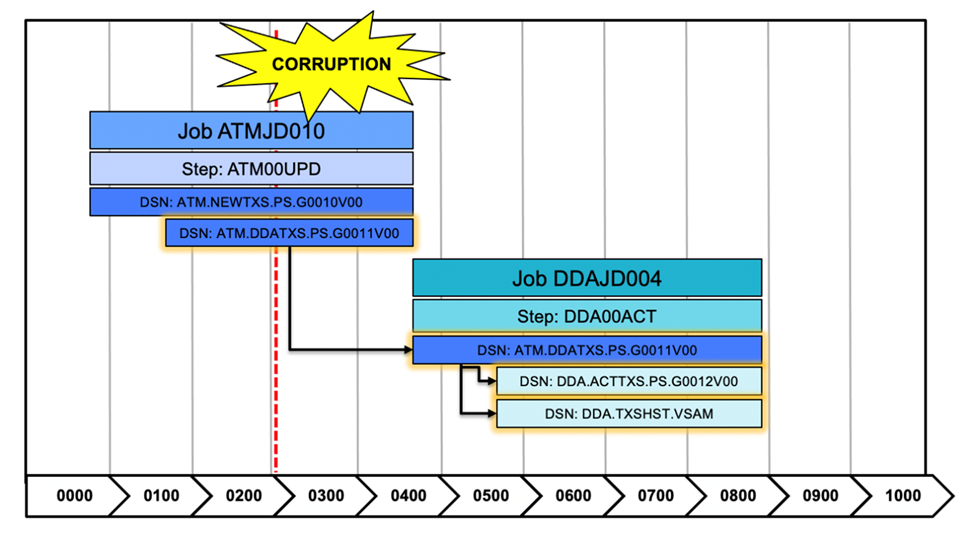
In addition to the Reverse Cascade Report, IZBR provides a similar view but going forward in time (Forward Cascade Report). This report is very useful to create a recovery plan for a data set that is being restored. The Forward Cascade Report can be run from the point in time that the data set is being restored and it will show all the work (even if it involves multiple applications) that needs to be rerun to bring the data set to a current state. The alternative would be to use the scheduler to rerun all jobs, which may cause unnecessary work to be run (jobs that had nothing to do with that data set) or work may be missed because the scheduler does not know the relationship of a data set to an application. If multiple applications are dependent on the data set any secondary applications may be out of sync with the restored data set.
In the use case of a catastrophic recovery scenario, let’s visualize how IZBR can enhance the IBM Z Cyber Vault solution. Note that not all IBM Z Cyber Vault capabilities will be described here. The complete documentation can be found in the IBM Z Cyber Vault documentation and Redbook. Rather, the use case will focus specifically on the IZBR capabilities to show how the product will support the effort and to compare what the alternative would be without IZBR.
In this use case the assumption is that the IBM Z Cyber Vault validates the system and application Safeguarded copies are produced once a day. This document is not intended to explain or describe IBM Z Cyber Vault, but it is necessary to review the validation processes since they are referenced. This description comes from the Getting Started with IBM Z Cyber Vault | IBM Redbooks. There are three types of data validation that are specific to each IBM Z environment:
- Type 1 validation – System data
Validate whether an LPAR can fully IPL from the restored volumes, checking out core parts of z/OS by enabling subsystems and logging into them.
- Type 2 validation – Data structures
Perform health checks, run scripts and tools to validate catalogs and other core parts of the system, check and validate Coupling Facility structures. Validate that key middleware, databases, and runtimes are operational. These data structure validations of CICS, MQ, Db2, IMS, and batch environments ensures the z/OS image can run applications, handle transactions, and process data. All these validations are needed to know that a system is fully operational.
- Type 3 validation – Application data
This validation is to ensure that application and user data stored in datasets, databases, or other subsystems is valid. This validation is the final step to ensure that a copy is not corrupted from malware, ransomware, or any other source of intentional or unintentional data corruption, and able to be trusted. These validations can be done by running numerous database queries, running batch programs and online transactions, and running other application tests to prove that data is available. It is the responsibility of the application, database, and technology teams to provide the appropriate tools and scripts to run these tests, which will be incorporated into the Cyber Vault automation framework to be executed.
In this use case, Type 3 validation of application data is utilized.
To begin, an alert is triggered when a critical business application fails validation during nightly Cyber Vault processes. Security and recovery personnel will use IBM Z Cyber Vault to do forensics to analyze the failure. In this use case the failure is determined to be pervasive, and the decision is made to do a total restore of the system and data from the last Safeguarded copy. This is a big decision and there will be many people involved in the overall recovery. This use case will focus on the recovery of the non-database managed data and how IZBR can help to ensure a more timely and accurate recovery process for this data and how IZBR surgical recovery can be used to recover any other data set that is required outside of the base Safeguarded Copy used for the system recovery.
Once again, security and recovery personnel will use IBM Z Batch Resiliency to recover the data and develop a recovery plan. (The questions that are presented to be answered are only a fraction of the questions that would be asked in a real-life scenario. These questions are primarily to help understand the use of IZBR in support of IBM Z Cyber Vault.)
What non-database managed data sets were open at the time of the Safeguarded Copy? The IZBR Cyber Vault Health Check report provides the answers to this question. This report can be run for the Safeguarded Copy that will be used for recovery. This report provides a list of all the non-database managed data sets that were open for output on that Safeguarded copy. The report could also be run against another Safeguarded Copy to see if there is a Safeguarded copy that is better to use for the catastrophic recovery. Alternatively, it could be used to determine if Safeguarded Copies are useful for a surgical recovery of any non-database managed data that is not usable in the primary Safeguarded Copy being used to recover the environment.
In addition to this report, the IZBR dialogue can be used to identify other Safeguarded Copies that can be used to recover non-database managed data that is in doubt on the primary Safeguarded Copy. Using IZBR from within the system running in the IBM Z Cyber Vault, a display similar to the ISPF 3.4 Data Set List will provide a list of all the Safeguarded Copies that contain one or more data sets. In addition to listing the Safeguarded Copies it also shows the open/close status of the data set on that copy. Using IZBR’s 3D Virtual Katalog feature (Patent Pending) IZBR identifies the correct volume where the data set resided for any Safeguarded Copy, even if it’s different from the current location in the catalog.
Without IZBR to provide this information it would be very difficult to know the state of the non-database managed data at the time of the Safeguarded Copy. As a result, many data sets may be restored in a “fuzzy” condition, and it is very likely that this would cause many data inconsistencies that may not be detected until much a later time, causing many more problems trying to correct. Without a tool like IZBR manually recovering individual data sets from Safeguarded Copies can be difficult and time consuming. As an example, in an SMS environment the data set may have resided on a different volume at the time of the Safeguarded copy than where the catalogue shows at the current time. Without IZBR’s 3D Virtual Katalog, it could be a time-consuming effort to locate the right volume in the Safeguarded Copy and to know whether the data set was open or close at the time of the Safeguarded Copy. These problems are magnified when time is your enemy.
It is almost certain that at the time of the recovery some other data sets may not be viable for use from the base Safeguarded Copy. If this happens, IZBR can be used to surgically recover any data set. This would include Db2 files, CICS VSAM files or virtually any data set that is on the Safeguarded copy. As described above, it is as simple as providing a data set name or mask and getting the list of the data sets. From that list you can put an “R” next to the dataset and generate the job to surgically recover the data set.
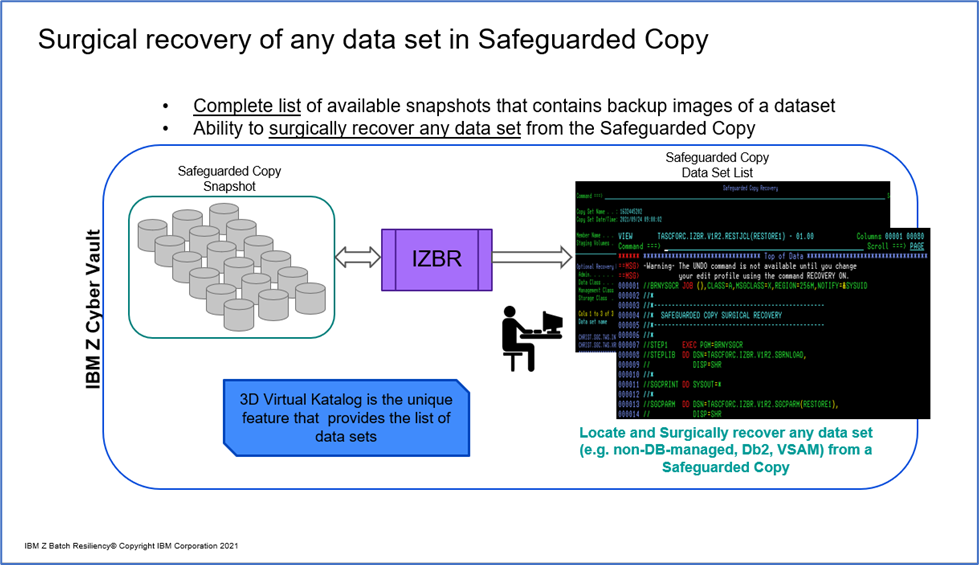
Of particular interest to the IBM Z Cyber Vault solution are IZBR’s Timeliner reports. The Timeliner report, specifically the Reverse Cascade Report, can be used, from a particular point in time, to look backwards for a data set and see all the jobs that have used or influenced this data set. It will display these jobs and show, for each job, the data sets that were used both as input or output. This information provides analytics to forensically help identify the points where a data set could have become corrupted.
What work needs to be rerun to recover to current for non-database managed data? Once the data set or data sets are recovered, identify the work that needs to be rerun to bring that data set in synch with the rest of the application. As in all the other steps of recovery, time is of the essence. It is important to get back to a current state as quickly as possible. Avoid runs of unnecessary work without, just as importantly, missing critical work that must be completed.
The IZBR Timeliner Forward Cascade report helps to identify the most accurate and efficient forward recovery plan. This report identifies all the work across all applications that is dependent on this data set. This will help to prevent running unnecessary dependent jobs from the scheduler if they have no dependency on the data that was restored and it will ensure that if there are other applications dependent on this data that those application jobs are also rerun.
Without the IZBR Timeliner Forward Cascade report the scheduler would be used to run ALL dependent jobs from the point of the restore. First, this could cause unnecessary work to waste resources and time. Secondly, the scheduler does not have a data set view of the applications. If there are other applications that depend on this data, they could be missed in the recovery process and cause more issues in the future.
In conclusion, the IBM Z Cyber Vault is a leap forward in providing a structure and foundation to ensure that many of the risks of ransomware, software and human errors or other forms of corruption can be mitigated. There are several hardware and software products necessary to allow this solution to provide the desired results.
IBM Z Batch Resiliency provides unique capabilities with patent pending features that further enhance this capability. The use of IZBR will ensure that when the time comes to utilize the IBM Z Cyber Vault in a critical moment that you can recover your data quickly and accurately from the IBM Z Cyber Vault. Without IZBR, this could prove to be difficult, time consuming and error prone. When time is of the essence and the stress levels are already high, IZBR helps to minimize the time and the angst when it comes to recovering data.
Originally published on the AIOps on IBM Z Community Blogs.