



Several techniques to move the needle
For some reason, technology experts are regularly claiming the end of the mainframe. When IBM announced the opportunity to run Linux on hardware mostly dedicated to z/OS, some thought that it was the sign that the platform will disappear slowly but surely. Today, we can attest that it was not. The Open Mainframe Project unites more & more experts from the mainframe world to leverage the best from Linux to push the limits of the mainframe even further.
The mainframe remains a costly platform to many, representing a single line in the IT budget. Depending on their size, companies adopt different approaches to deal with this budget line item. The smallest data centers often choose to exit the mainframe world by choosing distributed servers. As for the medium-sized data centers, they will turn progressively to outsourcing solutions; a future that IBM has prepared for with its new Mainframe-as-a-Service (MaaS) offering. But, companies who own large mainframe infrastructure will most likely continue to rely heavily on it, as it provides the best performance/security/cost ratio. In addition, the mainframe platform is the only one providing high availability and resilience as a built-in feature.
Even if the mainframe is a profitable platform, there is always room for cost optimization. I do choose to use the term “cost optimization” and not “cost reduction” as the latter promotes the unfortunate widespread misconception that reducing costs means lowering the quality of service. There are many ways to improve the return on investment of your mainframe platform, and in this article I will try to explain how.
Software performance optimization
Performance is a pervasive quality of software systems; everything affects it, from the software itself to all underlying layers, such as operating system, middleware, hardware, communication networks, etc. Software Performance Engineering encompasses efforts to describe and improve performance. With a software performance optimization approach, the idea is to modify a software system to make some aspect of it work more efficiently or use fewer resources. This method has direct impacts on the cost of the mainframe platform and the performance, but implies a lot of investment in time and human resources. Some specialized tools can help perform the job faster. A software optimization process can occur at different levels: design, algorithms and data structures, source code, build, compile, assembly… Some changes are fundamental which means they are harder to implement later on in a project. The best approach is to focus on the most profitable tweaks (small work for the highest gains). For example, at the source code level, rewriting sections can lead to high gains because of the “rule of thumb” known as the 80/20 rule. It states that 80% of the time is spent in 20% of the code.
Software urbanism
Software urbanism is a methodology designed to make sure that all software installed within your IT infrastructure brings the most added value possible. The idea is to make sure that every piece of software is at the right place, for the right cost and for the right need. It implies a complete study of your software portfolio to seek for underused software, functionality overlaps and architecture improvements (LPAR distribution). The initial investment is high, but so is the reward, in terms of cost reduction. To learn more about software urbanism techniques, refer to: Software Urbanism: A challenging but highly rewarding strategy and Software urbanism and rationalization: A lever to negotiate with ISVs.
Hardware limitation
To quickly reduce or control costs of their mainframe infrastructure, some companies choose to limit the capacity of their machines. Two methods are available: choose a machine with a maximum capacity close to your needs (or your budget limit) or use hard capping methods based on relative values or absolute values (i.e., Absolute Capping). In that case, you “virtually” limit your machine. Although these methods lead to instant savings, your performance will suffer from this limitation, especially in the case of unexpected critical workload increases.
Batch processing & Job Scheduling
Directly linked to IBM pricing method (invoice based on consumption peak during the month), batch processing and job scheduling can control your costs and improve your mainframe performance. On a mainframe, workloads don’t have the same level of urgency/importance. Some tasks performed by a software application can be delayed to run at another time of the day, where there are few critical tasks performing. Online tasks must run in real time, typically during the day, while batch processes can run at night when online activity is significantly lower. In some cases, the beginning of the month represents a period with the highest activity rate requiring you to move some tasks to run later in the month or on a week-end, when the activity level is lower. Efficient batch processing requires time to identify non-critical tasks and involves the help from the production department.
Licensing & contract optimization
One method that has no impact on your performance because it simply depends on your negotiation skills is to meet regularly with ISVs to work on your contracts. IBM proposes many types of contract (IOI, ELA, ESSO) but it’s not always easy to define which one is the best for your situation. For the pricing itself, IBM has many possibilities. Just for the Monthly License Charge licensing model, you have 13 pricing models:
- Advanced Workload License Charges (AWLC)
- Advanced Entry Workload License Charges (AEWLC)
- Country Multiplex License Charges (CMLC)
- Workload License Charges (WLC)
- Entry Workload License Charges (EWLC)
- Midrange Workload License Charges (MWLC)
- z Systems New Application License Charges (zNALC)
- Multiplex zNALC (MzNALC)
- zSeries Entry License Charges (zELC)
- Parallel Sysplex License Charges (PSLC)
- S/390 Usage Pricing
- Usage License Charges (ULC)
- Select Application License Charges (SALC)
- Details on the various pricing models can be found on the IBM software pricing website.
Currently, a growing number of companies are switching their contracts to sub-capacity pricing with their ISVs to reduce their costs. The principle is simple: pay for what you use. If you still have several contracts based on full-capacity pricing, it could be a good start to negotiate for a sub-capacity contract. Optimizing licensing & contract is complex and will be more detailed in a future article.
LPAR Capping
IBM Soft Capping is a feature to control the costs generated by the platform by setting a limit for each LPAR. This static limit is called Defined Capacity (DC) and works on a consumption average. It’s the first step to control your billing. This method requires a tight monitoring as well as time to configure and change the limits according to specific periods. IBM Soft Capping does have an impact on performance; when the limit is reached, workloads are delayed.
Group Capping
IBM defines Group Capping as follows: “Group Capping allows the definition of a group of LPARs on the same machine and a limit for the combined capacity usage by those LPARs.” If you set a limit of a group of LPARs, once it’s reached all LPARs will be capped according to their weight. This method implies performance risks if it’s not correctly monitored. You can combine Group Capping with LPAR capping to limit the impact of one LPAR in the group.
These two methods (LPAR capping & Group Capping) are the first steps taken by companies when it comes to controlling costs and performance at a mainframe system level. These IBM features are both easy to use and to implement but they lack flexibility.
LPAR Capping with an automated tool
Some tools can help manage your LPAR capping strategy by automatically changing your Group capping limits or Defined Capacity limits (LPAR level). Mostly, they are here to ensure that capping is handled safely when the limit is reached. Some workloads will be sacrificed in order to protect critical workloads. The resource consumption average will be reduced, hence the billing level. Performance is reduced but your SLAs will be respected.
LPAR Capping & Resource Sharing with an automation tool
Another option to control your software costs and your performance is to choose an automation tool that dynamically changes your resource usage limits according to your current consumption. LPARs don’t require the same processing capacity at all times. When one LPAR is under-utilized, system capacity available to you is lost. An automation tool can take unused capacity from one LPAR, and allow that capacity to be used by an LPAR running at, or near its full capacity. This means that your mainframe resources are always used at the right place at the right time, thanks to resource sharing. Unlike earlier tools, this kind of solution works continuously, not only during capping periods, hence avoiding capping altogether. Depending on how you use the tool (aggressively or conservatively), the balance between performance and costs will vary: An aggressive strategy will result in greater cost reduction, but may or may not increase performance, while a conservative strategy will result in less cost reduction but a greater increase in performance.
WLM policies
According to IBM, “with z/OS Workload Management (WLM), you define performance goals and assign a business importance to each goal. You define the goals for work in business terms, and the system decides how much resource, such as CPU or storage, should be given to it to meet the goal. Workload Management will constantly monitor the system and adapt processing to meet the goals”. WLM is a powerful tool to define and meet performance goals for your workloads. In essence, it’s a tool designed for performance but some companies are using it to control costs. To do so, they are using a WLM feature called “Resource Group”. In order to use this feature, you need first to assign tags to your workloads in order to group them into specific types. This method allows you to decide that a non-critical group of workloads will receive fewer resources to save it for more critical workloads. It’s a way to deliberately reduce the performance by setting a limit expressed in service units, % of LPAR or 1/100th of a processor… to reduce costs. Defining WLM policies is a complicated task that takes a lot of setup time. You also need to monitor it tightly and make it evolves as business goals can change over time. This method requires a great deal of expertise.
Summary
Choosing to run one method or another depends on the answers to these questions: Do I want to have an impact on costs? On performance? Do I want to balance these two aspects? Do I have time to spend on the implementation process? Will I have the sufficient resources for the required follow-up? Each method detailed above has its own unique impact on your infrastructure. On one hand, software performance optimization leads to a moderate improvement in performance and in cost savings but implies a lot of setup time and ongoing process management. On the other hand, hardware limitation leads to a certain amount of cost savings at the price of a sharp decrease in performance, but it’s quick to implement and requires minimal monitoring. When you decide to proceed with one of the methods described, you need to consider a matrix – savings vs performance vs setup time vs monitoring time – and choose the one that best fits your situation. Implementing all these methods is possible, but will require you to have substantial resources and a large team dedicated to managing them.
Here, below, I propose you a summary of all these methods and what it implies for your company:
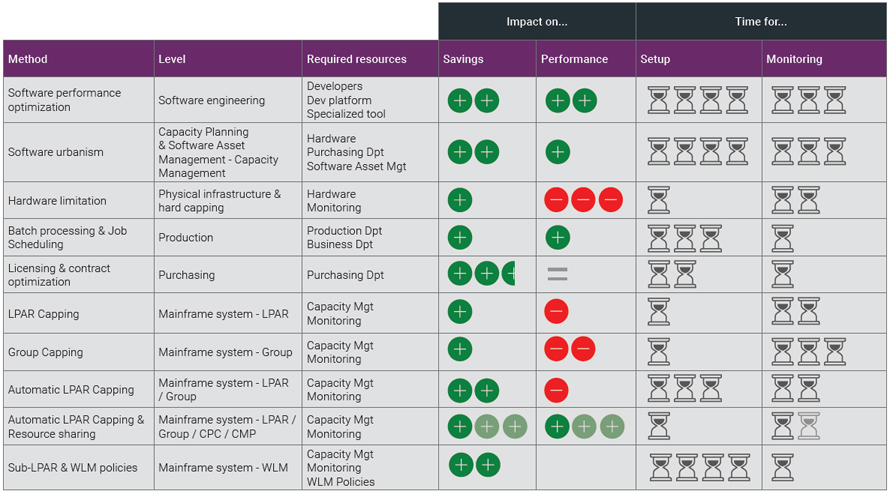
What about you? What are your techniques to move the needle between cost and performance? We will be glad to hear from your own experience.





0 Comments