



Artificial Intelligence (AI) and Machine Learning (ML) are the latest exciting technologies and buzz in the business and tech worlds, taking over from the past buzz like GDPR, analytics, IoT and Big Data. These topics have already (arguably) become mainstream interests for most large businesses, and for many smaller businesses, as well. And like these “past” buzzwords, AI and ML are not going away, and more importantly, are going to matter to your business at some point. Are they approaching mainstream now in 2018? Well, that’s another story altogether.
History
Most will realize that machine learning has actually been around for quite some time – in fact, the term was coined in the 1950s – when ML was not much more than a concept. Interest and understanding began and grew, but the compute power needed to start real experimentation did not exist. Not even close. Only recently has that level of compute power become available, and that is why there is an upsurge in business interest – everyone sees the potential, and realizing tangible benefits is tantalizingly close. Businesses have boatloads of data – data about their customers, their products and services, themselves, their competitors, and everything else under the sun. They’ve started running analytics on it and now they’re hungry to take the next step; to use it as an input for ML algorithms, and to develop the AI to obtain more valuable insight.
It’s all about the data
I have always been a big proponent of starting small; whether we’re talking about Big Data, IoT or analytics. There’s nothing wrong with starting small to get your feet wet, to determine whether or not you’re on the right track, if you have the necessary internal expertise available, etc. Starting small means that you’re actively doing something, as opposed to waiting (forever) until you’re sure everything is in place before moving forward at all.
But you do need your data – because it is, after all, all about the data. That’s why we’re doing this; to get something out of our data. And that something is business value – to predict or to suggest options or courses of action to achieve favorable outcomes – like improved customer satisfaction or increased profits. To paraphrase a 1980’s Al Pacino movie, “First you need the data, then you get the machine learning, and then you get the business value…”
Data location
Corporate data is all over the place; mostly because businesses rely on the best computing platforms for the jobs at hand. For example, data from transaction processing is often resident on the mainframe because the mainframe is the most powerful and cost-effective platform for that job. Similarly, other business data is server-based, either within local datacenters or cloud-based datacenters, or web-based, because the various business processes are served best by different computing platforms. Your business analytics repository may be on one platform, while your machine learning activity may take place on a different platform.
Data types

Figure 1: The Johari Window
Do you need to start with all of your data? Certainly not, but you are well advised to start with all of the types of data that you have (or need). What does that mean? Well, to answer that, let’s borrow from an psychological analysis technique introduced in the 1950s’ and applied more recently to business, science and politics: the Johari Window.
It nicely illustrates the pitfalls present in data analysis. Your end goal is obviously to make the best possible (correct!) business decisions based on your data. And that is the kicker; you may only be including a portion of the information that you actually need for proper analysis and decision making. So let’s have a look at these different types of data using the Johari Window:
Open area – your comfort zone; the arena in which you spend most of your time, measuring and analyzing known business and IT data. You may think this covers everything, but it often doesn’t.
Blind area – your blind spot or your organizational deficiency – something that can be addressed by new data, or new inputs. For example, if you’re analyzing your IT data, but you know you’re only including data from certain systems, and not all systems. You may choose to do this because you believe the data on your Linux servers to be the only important data. However, a business manager might tell you that the mainframe data is critically important, and must be included. And that might be a pain, because it’s on a different platform from your ML concerns, it’s in a different format, and so on. But what’s the point of doing ML at all if you’re ignoring important data? Well, the good news is that this oversight can be corrected by finding ways to include all available data for analysis – and there are technologies available right now that will allow you to do it.
Hidden area – another blind spot, but different in that you (and most people in your company) are unaware of it. For example, if you wanted to analyze all data including archived data, you may not know that one of your cloud service providers archives some of your data at a third-party site on tape cartridges. This is a tougher nut to crack, and could take considerable time and effort, as well as determined thoroughness. But it is still solvable using existing platforms, tools, techniques and personnel expertise.
Unknown area – another blind spot, but a much worse one – one that you are unlikely to discover ever, using any of the techniques you have ever used to solve any other business challenges up to this time. For example an insurance company experiences slightly different claim patterns from varying clients – something that doesn’t even closely fit any of the insurer’s fraud scenarios, and may not actually be fraud related at all, but is still costing the firm money. Data analysis may not reveal anything meaningful, due to incomplete data. The unknown area may well be where the greatest insights can be found – those which could yield new levels of business efficiency, revenue and profitability. Further, the unknowns may only be solvable using machine learning techniques – using all types of data.
The bottom line is that you really need to know about all of your relevant data. And in some cases, that means going beyond conventional server-based data, into the realms of social media, email and text data. You can’t ignore some types of data because they’re inconvenient to obtain, and you can’t just assume that the data at hand is the only data that matters. You need to know your data, and that is best done up front.
About Artificial Intelligence and Machine Learning
AI and ML have been around for a while; but what makes things different now is the increase in compute power, and the massive increase in the amount of data available for model training, both key aspects of deep learning that is all the rage in the ML world. It all starts with a neural network; technology very loosely based on the human brain, but in reality, just simulating the brain in the most basic way – a system that can learn based on inputs. The basic building block is the neuron – a mathematical parallel to the organic neuron in the human brain (Figure 2).

Figure 2 – The Neuron
A biological brain neuron is a single cell with dedicated electrical inputs and electrical outputs. Mimicking this conceptually, an artificial neuron is a mathematical function with one or more dedicated value inputs and a value output. A biological neuron will “fire” or pass on information based on certain energy levels within the neuron, induced by its inputs. Similarly, an artificial firing is based its mathematical function and how it is affected by its weighted inputs.
A neural network is a complex association of a large number of neurons. Figure 3 shows how artificial neurons are connected and arranged in deep learning neural networks. Two neurons are linked (Figure 3, top center) where an output connects to an input; while multiple neurons are arranged in layers (Figure 3, top right), where multiple outputs connect to multiple inputs. Larger structures (Figure 3, bottom) are purposely organized in layers (including ‘hidden’ layers) – where multiple outputs connect to multiple inputs.
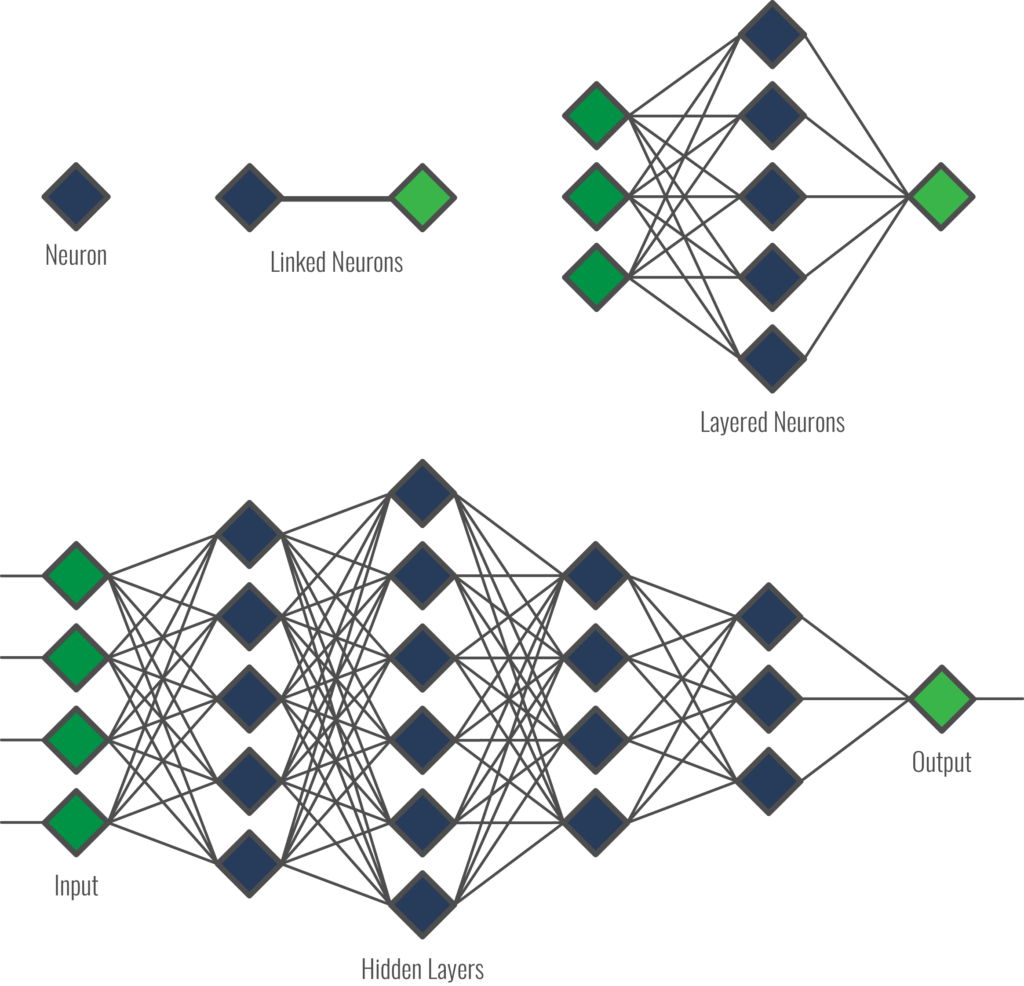
Figure 3 – Neurons (top); the neural network (bottom)
Figure 3 (bottom) is a representation of a neural network, albeit a very simplified version. An actual network might have dozens (hundreds?) of layers including hundreds of nodes, or more. It also does not show the weightings of the connections between each neuron. Backpropagation is an example of weighting, where the output of a node is based upon its contribution to overall network error. Needless to say, such a network is exceedingly complex and requires specialized expertise just to grasp some of the concepts.
Challenges
The nature of “deep learning” goes something like this – an algorithm can be taught to tell the difference between two objects, A and B. But to get to that point, much trial and error takes place. Many algorithms that cannot tell the difference between A and B, or are just not very good at it, are discarded, and new algorithms are designed. Through this process, however, practitioners eventually train algorithms that can tell the difference between A and B. This is an over-simplification, of course, but points to a major issue.
It has been said that machine learning has become a form of alchemy – and that is not really an unfair comparison when you consider that often, machine learning practitioners do not know why some of their algorithms work, while other algorithms don’t work.
Indeed, machine learning visionary and expert Judea Pearl insists that today’s deep learning activity consists mostly of curve fitting – that is, finding regularities in existing data points, and fitting the best curve to them. Further, he says that today’s deep learning scientists and practitioners focus chiefly on prediction and diagnostics, leaving concepts needed for true intelligence like casual reasoning and cause-and-effect, on the back burner.
Practitioners might strongly disagree, and certainly the curve fitting metaphor diminishes the incredible strides being made today, but he did have a point – we’re no closer to a real thinking “Terminator” type machine now than we were in the 1950s. But to be fair, this is still pretty new stuff.
Moving ahead
Where are we now? Well, today ML and particularly deep learning are the driving forces behind AI. Our current efforts involve AI (actual intelligence), because a human is needed to come up with the way the AI (artificial intelligence) would be used. The AI (actual intelligence) knows which data to feed the AI (artificial intelligence); the final output is in fact AI (augmented intelligence), since AI (actual intelligence) is required to interpret the results.
Gartner’s “Hype Cycle” has given us a way to express the progress of new technology as it progresses from the start, or trigger, through to successful adoption and productivity. For ML, despite the fact that we’ve known about it for decades, only recently have we been able to begin testing the theories. And while there have been some successes, it has been mostly done at great cost, and today cannot be considered to be business mainstream. Many businesses are hiring data scientists and ML experts, but many will fail at least in their initial forays into ML. What that means is that we are still riding the first wave of the hype cycle. The “trough of disillusionment” may not describe today’s ML and AI landscape, because we’re still heavy into the high expectations phase.
Geoffrey Moore’s “crossing the chasm” concept gives us a good way to show how new technologies are being adopted, and becoming mainstream. The early innovators show some success, again, by spending tremendous amounts of money and taking literally years to start showing any form of ROI. That’s happening right now – think IBM’s Watson, Apple’s Siri, Google’s Alexa, open-source Sirius, automated chat bots and so on. But are we inching towards widespread use and success? Um, no. We’re in the chasm right now.
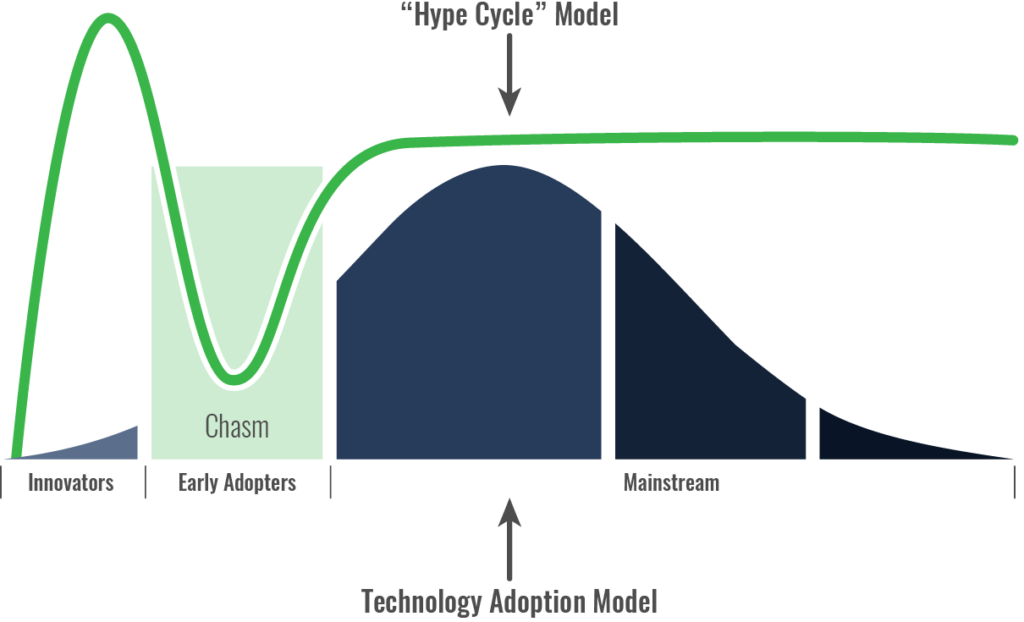
Figure 4: Machine Learning and the Chasm
Conclusion
Success depends upon the quality of business data, and for AI and machine learning to deliver the goods; IT organizations must leverage all types of relevant data. Starting small with a subset of data is possible, but all relevant types must be eventually included, whether that data is from server farms, mainframe systems, social media, or other sources, if results are to be truly meaningful.
It’s still early in the game, but make no mistake about it; machine learning isn’t going away, and as it is refined, it is going to become a prerequisite for business success in the coming years. At some point in the near future, a company that is not engaging in ML and AI will be conceding competitive advantage to their rivals. And if you’re one of those companies, it won’t end well for you.





0 Comments